React was one of the first front-end frameworks I worked with. Soon after, I found Elm and I absolutely fell in love with it. Then my team and I started to move apps from React into Elm. This is a pretty fun problem, because there are a few ways to go about it: have Elm consume the React App piece by piece; have React consume the Elm App piece by piece; or replace the app entirely. I noticed there isn’t a lot of recent work on this topic. So I wanted to make a guide for anyone trying to make this transition. Elm is a wonderful language and so is React, so being able to use them in tandem is a powerful choice!
If you’ve used React, you most likely have used (or got started with) our friend, create-react-app. And if you’ve used Elm, you may have used the similar package, create-elm-app. Both of these packages are a great way to get started developing with Elm & React quickly, without going through the work of setting up a custom environment. They both provide eject, a script that permanently changes your create-LANG-app from a single-dependency on the tool, to all of the packages that bundle includes with their respective configurations.
For the purposes of this article, I’m going to assume you have some familiarity with React. As for Elm, I will write all the steps assuming you’re new to the language. And even if you’re already familiar with Elm, this should be helpful guide for transitioning between the two.
Code in Github – Elm React Components Package – Learn Elm Here
🌱 Getting Things Ready
Before we begin to replace any React with Elm, we will need to get Elm setup on your system. Head over to the Elm install instructions and download it for your OS. Once you’ve done that, jump into your existing React project. For this tutorial, I’ll use my own simple todo list app built on Webpack 5 with Webpack Dev Server. The full source for this is available in my GitHub repo.
If you bootstrapped with create-react-app, now is the time to run npm eject. Remember, this cannot be undone. Once you’ve done that you can either run npm i elm or add the following line to your package.json:
"elm": "^0.19.1-5"Don’t forget to update the version to whatever is most current. As of writing, this is the most recent npm package.
After that, we’ll need to generate an elm.json file by running the elm init command in the root directory (same place as package.json) of your project.
elm initFinally, let’s add the elm-webpack-loader to our webpack config. We’ll install the packages and then add them to our webpack config.
npm i elm elm-webpack-loader elm-hot-webpack-loaderYou can find this under config/webpack.config.js. Scroll down to module.rules and add a new rule before the test for js|mjs|jsx|ts|tsx. There’s more to configuring elm-webpack-loader than I’m going to show here, but the following code will get you up and running:
{
test: /\.elm$/,
exclude: [/elm-stuff/, /node_modules/],
use: [
{ loader: 'elm-hot-webpack-loader' },
{ loader: 'elm-webpack-loader' },
],
},And with that, you have successfully set up your project to have both React and Elm apps. Yay for you! 👏 The best verification we can have is looking at the Elm compiler, which has started a nice conversation about a bug in my Elm app:
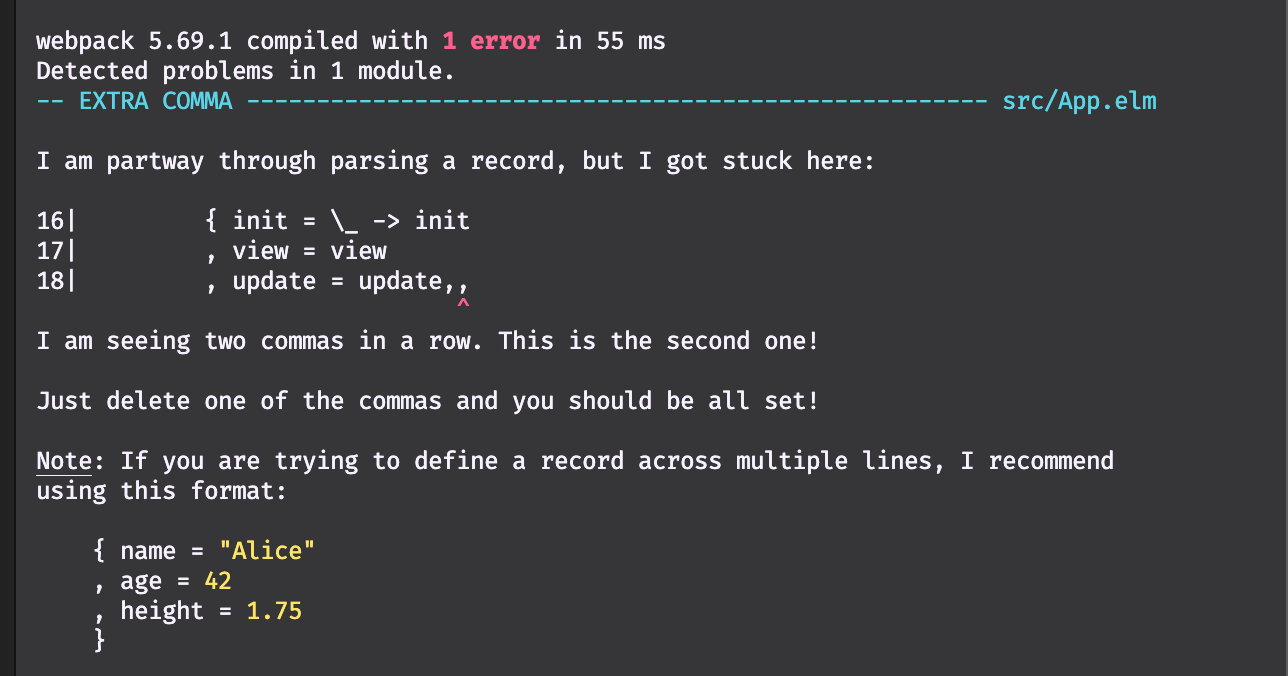
⚛ → 🌳 Replacing a React App with an Elm App
In a perfect world, we could just replace our React App with our Elm App. While this probably isn’t the most likely case, it is an option I have used many times. This is especially good for simple apps or just low-risk ones. One amazing benefit of Elm is that there are no runtime exceptions, so you won’t be risking the entire app breaking when you deploy.
To get started, create a file called App.elm in src. This will replace your App.js. The React code for this example app is over on GitHub. Below is the Elm version of the app:
module App exposing (main)
import Browser
import Html exposing (Html, div, form, h1, input, li, text, ul)
import Html.Attributes exposing (class, type_, value)
import Html.Events exposing (onInput, onSubmit)
---- PROGRAM ----
main : Program () Model Msg
main =
Browser.element
{ init = \_ -> init
, view = view
, update = update
, subscriptions = \_ -> Sub.none
}
init : ( Model, Cmd Msg )
init =
( initialModel, Cmd.none )
initialModel : Model
initialModel =
{ items = []
, inputText = ""
}
---- MODEL ----
type alias Model =
{ items : List String
, inputText : String
}
type Msg
= ChangedText String
| SubmittedForm
---- UPDATE ----
update : Msg -> Model -> ( Model, Cmd Msg )
update msg model =
case msg of
ChangedText text ->
( { model | inputText = text }, Cmd.none )
SubmittedForm ->
let
items =
model.inputText :: model.items
in
( { model | items = items, inputText = "" }, Cmd.none )
---- VIEW ----
view : Model -> Html Msg
view model =
div [ class "App" ]
[ h1 [] [ text "Todo List" ]
, viewTodos model.items
, viewTodoForm model.inputText
]
viewTodos : List String -> Html Msg
viewTodos items =
ul [] (List.map (\item -> li [] [ text item ]) items)
viewTodoForm : String -> Html Msg
viewTodoForm inputText =
form [ onSubmit SubmittedForm ]
[ input [ type_ "text", onInput ChangedText, value inputText ] []
, input [ type_ "submit", value "Add" ] []
]
With that in place, let’s hop into our index.js file and change the ReactDOM.render(...) call to one to initialize Elm. First, import the Elm app at the top of the file:
import { Elm } from './App.elm';You can then call Elm.MODULE_NAME.init(...) to tell Elm which DOM node to initialize on.
Elm.App.init({ node: document.getElementById('root') });
And with that, the React App will be replaced with a shiny new Elm App to track our todo items. But it’s not always the case that a full replacement is the best or safest way to transition from React to Elm. Let’s take a look at slowly consuming a React App with an Elm App.
🌳 > ⚛ Consuming a React App within an Elm App
Although there isn’t a great way to load a React component within an Elm app, Elm provides ports to let us interact between the two. My favorite way to move a React app into an Elm app is to move the app state into the Elm app and then slowly consume the behaviors of the React app. In this example we’ll put the list items in the Elm app, but we will leave displaying the list and adding new items to the React app. Let’s get started by created an elm app in App.elm with a model to hold the list.
module App exposing (main)
import Browser
import Html exposing (Html, div)
---- PROGRAM ----
main : Program () Model Msg
main =
Browser.element
{ init = \_ -> init
, view = view
, update = update
, subscriptions = \_ -> Sub.none
}
init : ( Model, Cmd Msg )
init =
( initialModel, Cmd.none )
initialModel : Model
initialModel =
{ items = []
}
---- MODEL ----
type alias Model =
{ items : List String
}
type Msg
= SubmittedForm
---- UPDATE ----
update : Msg -> Model -> ( Model, Cmd Msg )
update msg model =
( model, Cmd.none )
---- VIEW ----
view : Model -> Html Msg
view _ =
div [] []To pass data to/from JavaScript to Elm, we’re going to need to add two ports. On the first line of App.elm add port before module. This leaves us with port module App exposing (main). Now let’s add two ports, one for receiving a string from JavaScript to add an item and the other for passing a list of strings back to JavaScript for displaying them. These two ports look like this:
port addItem : (String -> msg) -> Sub msg
port sendItems : List String -> Cmd msgNow let’s add the behavior for adding a new item to our update function. This implementation looks almost identical to the one for replacing the elm app, except our SubmittedForm type will also contain a string. We’ll have this value passed in from JavaScript and then call sendItems with the new list of items to update our React app.
type Msg
= SubmittedForm String
update : Msg -> Model -> ( Model, Cmd Msg )
update msg model =
case msg of
SubmittedForm newItem ->
let
items =
newItem :: model.items
in
( { model | items = items }, sendItems items )The last thing to do is to add a subscription which will be called whenever the addItems port is sent from JS. Change our Browser.Element function to call subscriptions = subscriptions and then create a new subscriptions function below. This function will call our addItems port with the local Msg to send the string to. That function is SubmittedForm and the implementation is as follows:
subscriptions : Model -> Sub Msg
subscriptions _ =
addItem SubmittedFormJavaScript & React
That’s all there is to do on the Elm side of things. Now let’s shift our focus back to our index.js file. We’re going to render both our Elm App and our React App, but the Elm app will only be responsible for holding the state. First, we need to assign the Elm app init call to a variable so that we can access our ports. Once we have that, we can pass the ports into our React component as props.
const elmApp = Elm.App.init({ node: document.getElementById('elm-root') });
ReactDOM.render(<App ports={elmApp.ports} />, document.getElementById('root'));The last step is to update our React component to use the Elm ports. Because our addItem port takes a string, the only change we have to make in the React component is to replace our addItem function with a reference to ports.addItem.send. We first get ports by destructuring it from props.
const App = ({ ports }) => {
const [items, setItems] = useState([]);
const addItem = ports.addItem.send;
...
}To receive the updated list of items from Elm, we’ll need to subscribe to our sendItems port. This subscription will pass a list of items, which I will just put in local state using a useState hook.
ports.sendItems.subscribe((items) => setItems(items));And with that, we have successfully moved our React app state into an Elm app, which will allow us to take it apart piece by piece, until we only have the Elm app left. If I were to continue this, the next thing I would do would be to move the list display into the Elm app. Finally, we could move the form over and eliminate the React App altogether.
⚛ < 🌳 Consuming an Elm App within a React App
Finally, there is the option of keeping the main app in React and slowly pulling in parts of Elm. I don’t prefer this method, because Elm doesn’t have a component-based model like React. In my opinion, it makes this a less natural transition. That being said, sometimes I find that this is the best way to go for a large and complex React app. There is a pretty nifty npm package that let’s you use an Elm app as a React component. If you don’t like this solution, you can use ports like we did in the previous example. Ports might be the better option, but this package will let us get running quickly. And since we’re talking about transitioning to Elm, the faster choice seems better to me.
Go ahead and run npm i @elm-react/component. This package includes the function wrap that will let us wrap our Elm app in a React component that will convert props into the ports we define in our Elm app. Pretty cool, right? At the start of our App.js component, import the function and our Elm app.
import wrap from '@elm-react/component';
import TodoList from './TodoList.elm'; After that, we can define a new component by passing our Elm app to the provided wrap function.
const TodoListComponent = wrap(TodoList);And with that, you can use <TodoListComponent /> within JSX, just as if it were a React component. Let’s replace the <Todos /> react component with our elm one.
<TodoListComponent updatedItems={items} />updatedItems will be the name of the port in our Elm app. This port will work exactly like the subscription we created in the previous example.
The Elm “Component”
Let’s hop back over to our Elm app and change it to a port module on the first line. This leaves us with the full component looking like this:
port module TodoList exposing (main)
import Browser
import Html exposing (Html, li, text, ul)
import List
---- PROGRAM ----
main : Program () Model Msg
main =
Browser.element
{ init = \_ -> init
, view = view
, update = update
, subscriptions = subscriptions
}
init : ( Model, Cmd Msg )
init =
( initialModel, Cmd.none )
initialModel : Model
initialModel =
{ items = []
}
subscriptions : Model -> Sub Msg
subscriptions _ =
updatedItems NewItems
---- PORTS ----
port updatedItems : (List String -> msg) -> Sub msg
---- MODEL ----
type alias Model =
{ items : List String
}
type Msg
= NewItems (List String)
---- UPDATE ----
update : Msg -> Model -> ( Model, Cmd Msg )
update msg model =
case msg of
NewItems items ->
( { model | items = items }, Cmd.none )
---- VIEW ----
view : Model -> Html msg
view model =
ul [] (List.map (\item -> li [] [ text item ]) model.items)
First take a look at line 42, where we define the port updatedItems. This name needs to match the name of the prop we passed into our wrapper React component. Because we’re passing in an array of strings, we’ll make it a List String type in Elm. Then we’ll define our subscriptions function, as we did before, to call updatedItems with the NewItems Msg we define below.
NewItems has a List String argument, which will match our port. Lastly, we move to our update function to define the behavior when a NewItems Msg is received. We’ll take in the list as items, locally, and we’ll update the local model state to this new list.
Then for our view we need only to display a list of the items in our todo-list. This will be a simple ul with a map of the list items. And that’s it! Startup the app and you should see the list displayed in Elm, while maintaining the state in the React app.
🌳 Conclusion
I hope that’s enough to get you up and running. Any way you go about it, I think the tooling is really great for Elm’s interop with JavaScript. In my opinion, keeping your interactions between the two to a minimum is best, because you’ll be missing out on the amazing runtime safety that Elm offers. That’s one of the biggest draws to Elm for me, so I try not to use ports as much as possible. However, you definitely have to, and being able to make the two interact while replacing an app is vital. So I think any of these methods would serve you well.
I prefer to put my app state into Elm and use React for interactions. Essentially eating the app from the top down. But the elm-react-components package is fantastic and easy to use, so if you’re wanting to start there, especially if you’re new to Elm, I think it’s a great option.
Best of luck! Happy Elming.
Footnote: Msg and msg
While reading this, it occurred to me that I change between Msg and msg regularly in Elm. When I was learning Elm I found this to be pretty confusing, so I wanted to clarify. In Elm, Msg is a concrete type that you define in your module. In all of the Elm examples here (and most places) you’ll see a type Msg line right above our update function. These are all of the events that can update the app’s state.
The lowercase, msg, on the other hand can be any type. You can think of it as a placeholder for “any” type that may later exist. This is exemplified in the view functions in this code. In the case that the Elm app had to handle state updates, the type was Html Msg, because the DOM would call a Msg to update the todo items when a form was submitted. However, in the 3rd case, I used Html msg, because there are no events in our Msg that the DOM would call.
This week I had received a code review from a teammate to add a @spec to a start_link function I wrote for a GenServer. My start_link function will take a keyword list, try to get the values :first_name and :last_name with defaults, and then call GenServer.start_link/2 with __MODULE__ as the module and those values as the initial state. This GenServer looks like this:
defmodule JoelServer do
use GenServer
def start_link(opts \\ []) do
first_name = Keyword.get(opts, :first_name, "Joel")
last_name = Keyword.get(opts, :last_name, "Abshier")
initial_state = %{
first_name: first_name,
last_name: last_name
}
GenServer.start_link(__MODULE__, initial_state, opts)
end
def init(state) do
{:ok, state}
end
endWhat I would like to do is add a @spec to describe how to use this function. Luckily, in Elixir we have Dialyzer to make this easy. Dialyzer is a static analysis tool within Erlang/Elixir. One feature of Dialyzer is to suggest @spec annotations for a function. Let’s see what it thinks for this:
@spec start_link(keyword) :: :ignore | {:error, any} | {:ok, pid}
def start_link(opts \\ []) do
...
endWhile that’s correct, a more specific @spec is valuable to us. Let’s look at how we can do that.
📨 Arguments / Input Type
Let’s take a look at the keyword list we’re passing in. It technically doesn’t matter to us which options are passed in, in addition to :first_name and :last_name, however if the spec were to define those specific keywords, we could catch any issues and/or typos while writing the code. Let’s define a private type that lists our keywords. First, add the typep definition and then update the @spec accordingly.
@typep start_opt :: {:first_name, String.t()} | {:last_name, String.t()}
@spec start_link(opts :: [start_opt]) :: :ignore | {:error, any} | {:ok, pid}
def start_link(opts \\ []) do
...
endNow if you try to call JoelServer.start_link(title: "Mr.") you’ll get a Dialyxir warning saying something like this:
([{title, <<77,114,46,32>>}]) breaks the contract (options::[start_opt()])That’s pretty cool! Now the next time someone on my team has to use this GenServer, they’ll be told exactly how to use it while calling it. But what about the return type?
📬 Output / Return Type
Now for the reason you’re here. A co-worker pointed me toward a type in the GenServer docs on_start/0. We can use this to replace the list of return types at :ignore | {:error, any} | {:ok, pid}. This lets us define our start_link with the return type as Elixir’s GenServer.start_link.
@spec start_link(opts :: [start_opt]) :: GenServer.on_start()I love this, rather than managing our own list of types for each GenServer I define. If you’re working with a Supervisor, we are also given Supervisor.on_start/0. If you want to allow any options allowed by a GenServer or Supervisor, you’ll also find options/0, option/0, init_option/0, and so on.
🐰 That’s all the GenServer we have today, folks
Anyhow, this might be pretty basic, if you’re familiar with Elixir. But I thought it was exciting to be told about these and wanted to share it. A lot of Elixir packages, especially the core library, have excellent hexdocs, so I’m going to make a habit of paying closer attention to the @specs on them for when I can take advantage of types like this.
I’ll probably be writing some more shorter posts like this. It’s a bit basic, but I’ll just make a Today I Learned category here on the blog, so you can check those out.
If you have any short tips like this I’d love to hear about them. I’m new to the language, so I’d love to learn! Thanks for reading! 🧪
– Joel Abshier
“Flow allows developers to express computations on collections, similar to the Enum and Stream modules, although computations will be executed in parallel using multiple GenStages” [Flow HexDocs]. This allows you to express common transformations (like filter/map/reduce) in nearly the same was as you would with the Enum module. However, because Flow is parallelized, it can allow you to process much larger data sets with better resource utilization, while not having to write case-specific, complex OTP code. Flow also can work with bounded and unbounded data sets, allowing you to collect data and pipe it through a Flow pipeline.
🥚 An Anecdotal Experience with Flow
Last summer, about 3 months into learning Elixir, I found myself in the middle of a project where I needed to collect product data from 5 different tables in a MSSQL Database and build a NoSQL database of products. I needed to process over 400,000 products daily. In addition to flattening the data, business rules for pricing, shipping restrictions, swatch options, etc. needed to be applied. We then shipped the data to our search provider, Algolia (amazing product btw). So let me use this story to make a case for Flow.
A co-worker of mine took an initial attempt at this project using NodeJS, but after getting about halfway through, we were already certain that it would not be performant enough. At this point we decided to develop the data processing pipeline in Elixir. Because we were both new to the language, we used Elixir’s Enum.map/2 and Enum.reduce/3 liberally, without any application of OTP. Surprisingly, we found that even with our extremely basic setup we were able to cut the time of the job down from over three hours to about 15 minutes.
Flow to the rescue!
However, we still weren’t completely satisfied with the performance of the tool, and we wanted to apply OTP to make the processing of our products concurrent. After reading Concurrent Data Processing with Elixir we decided to use Elixir’s Flow package combined with a series of GenStages. Our GenStages were fairly simple, consisting of a producer responsible for pulling product ID’s from a service bus, a consumer/producer responsible for collecting the product data from the database tables, another consumer/producer responsible for applying business rules and flattening the product data, and a consumer responsible for saving the data to the NoSQL database.

We do most of the data transformations in the second producer/consumer. This is where we applied our business rules for pricing, shipping, etc. and flattened our data. Underneath this Producer/Consumer we used Flow to add more concurrency to the processing. After massaging some of the parameters for how many concurrent processes Flow will use, we were able to process all of our product data in about 30 seconds, down from over 3 hours from NodeJS (which isn’t really a fair comparison, but aren’t big numbers are fun).
🐣 Your First Flow Pipeline
Let’s take a look at the power that Flow can provide you without much overhead. In this example, we’re going to be looking at a dataset of information on every DC Comic Book release. You can download it for yourself over here to follow along. Let’s create an application to go through the dataset and get the list of comics written by each specific author. I’m going to treat comics with multiple authors as a unique author, for simplicity’s sake. Start by creating a new mix project:
mix new comic_flow --module ComicFlowLet’s navigate into the root directory and run iex:
cd /comic_flow
iex -S mixLeave that for now and let’s open up lib/comic_flow.ex. In here, you can remove all of the code within the module and replace it with a new function called get_writers.
defmodule ComicFlow do
def get_writers do
# TODO
end
endThe file we’re going to read is in CSV format, and that’s going to need decoding. Rather than try to figure that out, let’s add the CSV package from hex.pm to our mix.exs file.
{:csv, "~> 2.4"}Now, back in get_writers we can read the data a stream:
File.stream!("dc_comics.csv")And then we can call CSV.decode!/2:
File.stream!("dc_comics.csv")
|> CSV.decode!()This next step is a little bit nasty, but it’ll work for the sake of example. The 2nd column of our CSV is the name of the comic and the 7th is the writer. We’re going to reduce over the list of comics and create a map of authors with their list of comics. This gives us a final get_writers function that looks like this:
def get_writers do
File.stream!("dc_comics.csv")
|> CSV.decode!()
|> Enum.reduce(
%{},
fn [_cat, name, _link, _pencilers, _artists, _inkers, writer | _tail], acc ->
Map.update(acc, writer, [name], &[name | &1])
end
)
endLet’s test
Perfect! Let’s go back to our iex terminal and run this code. I’m going to time it using the Erlang :timer.tc function. To time function calls, I’m using this method. If you want to learn, that’ll take you about 2 minutes to read. I got an average time of ~171.25 seconds, with a minimum of 65 seconds and a max of 244.
Ouch. I’m not happy with that time, especially if the dataset gets larger. And if DC keeps releasing comics every year, it’s just going to get progressively worse. Enum has to load everything into memory in one fell swoop before reducing. When this happens, not many system resources are being used, as we’re just waiting for the entire stream to be read in. But what if there was a way reduce over our collection while the stream was still read in? That’s where Flow comes in. Let’s start by converting our stream into a Flow.
To Flow we Go
def get_writers do
File.stream!("dc_comics.csv")
|> CSV.decode!()
|> Flow.from_enumerable()
|> Flow.partition(
key: fn [_cat, _name, _link, _pencilers, _artists, _inkers, writer | _tail] ->
writer
end
)
endFlow.from_enumerable/1 does the work of converting our data into a Flow, using the collection as the producer for the pipeline. There are options to configure the parallelization of the pipeline, but for now we can leave it without arguments. The next step is the Flow.partition/1 function. Partition is probably the trickiest function to use in Flow. In a simple case, like a tuple, it will default to taking left as the key. In our case, we want to specific the key that the partitioning will happen on, which will create the right hash tables. I like to think of this as “creating a path to the key.” In our example, the data is just a list, so we’ll destructure writer and return it back as the key.
Enum.Reduce -> Flow.reduce
Finally, we’ll convert our Enum.reduce into Flow.reduce. The functions are largely the same, with the primary exception being that Flow’s reduce has a function to return the initial accumulator, as opposed to the enumeration given to Enum.reduce.
def get_writers do
File.stream!("dc_comics.csv")
|> CSV.decode!()
|> Flow.from_enumerable()
|> Flow.partition(
key: fn [_cat, _name, _link, _pencilers, _artists, _inkers, writer | _tail] ->
writer
end
)
|> Flow.reduce(
fn -> %{} end,
fn [_cat, name, _link, _pencilers, _artists, _inkers, writer | _tail], acc ->
Map.update(acc, writer, [name], &[name | &1])
end
)
|> Enum.to_list()
endAnd lastly you’ll notice that we called Enum.to_list() Calling this function will execute the Flow in parallel and return back the file result. You can also use Flow.run(), but it will return an atom indicating success/failure, rather than the data from the flow.
After changing to Flow, the time to run through all of DC comics is now averaging 2.902 seconds. That’s about 1.7% of our initial time! Wow! That’s pretty cool.
🐥 Unleash the Flow
On one hand, there is a lot more to learn with flow and I’m sure you’ll run into some odd situations along the way where you’ll have to duke it our with Flow.partitiion, but on the other hand, you’re now mostly equipped to start implementing reliable, concurrent code with Flow. And the best part is, you didn’t have to wrap your head around the systems required for this concurrency, you are simply able to utilize functions that are nearly identical to the functions you already use on collections delay.
I’ve personally had a ton of fun using Flow for work and for sport. Like all things, Flow isn’t a silver bullet, and there are many times I still need to write concurrent code. However, for many applications, using Flow would provide a path to running highly-concurrent code without having to juggle a lot of complexity and without having to pay the price to build those solutions from scratch. Hopefully you can find a place for Flow in your own projects!